

Machine Learning Process And Scenarios: Introduction
Things in machine learning are repeated over and over, and hence machine learning is iterative by nature. Therefore, to know machine learning, one has to understand the machine learning process. The machine learning process is a bit tricky and challenging. It is very rare that we find the machine learning process easy. The reason for it being so complex is very clear, since a large amount of complex data is involved and out of which we try to find out meaningful predictive patterns and models.
That’s why this is dealt by data scientists who are actually specialists in this field, as I mentioned in my last article. In that article, I also mentioned how rewarding a machine learning process could be. The benefits out of this process could be outstanding, but we should also keep in mind that the process may not always succeed and possibly fail, but that’s too rare. In this article, let’s focus on the machine learning process and scenarios used.
Series
We’ll try to cover the topic and machine learning concepts, processes and scenarios including terminology in a form of series. This is the second article of the series and will largely focus on the machine learning process and scenarios. Below are the articles that we’ll follow including more information about machine learning.
1. Introduction To Machine Learning
2. Machine Learning Processes And Scenarios
3. Machine Learning : Deep Dive
Baseline The Need
In machine learning, asking the right question and knowing the correct answer is the most important. We should know what question to ask and this is the most important part of the process. After that, we should ask ourselves whether we have enough and correct data to answer that question. If you ask the wrong question or you do not have enough or correct data, the answer you will get can never be what it should be and what exactly is expected.
For example, if we take an example of internet banking transaction frauds, we ask ourselves how we can predict that a transaction is going to be fraudulent. Maybe, the case was that a large piece of predictive data is based on which city the customer resides in or what is his occupation or even how long he lives at his current address.

We might not have all this complete data, and we may also not get this data until some point. In that case, we should ask ourselves whether we have enough data to start or have at least the correct data. If we don’t have any of these, then we are not going to get the result or the answer we are looking for from the machine learning process.
Then, we should also ask ourselves what the criteria would be in order to define the success, as at the end of the process we only get the model out of data, that only predicts and not exactly gives us the answer. So, we should ask the question of how much better those predictions should be for the entire process to be tagged as successful.
In case of our example, if we find that we are sure about the fraud prediction in almost 16 out of 20 cases, then is this fair enough? Or what about 14 out of 20 or should it be 18 out of 20? How do we decide this? Knowing the correct answers to these questions is really important, as without them, we won’t get the desired result and will never know if the process is complete or whether we are done with it, getting an actual predictive model.
Machine Learning: The Process
If we go into details of machine learning process, firstly we identify, choose and get the data that we want to work with. For our example, we would often need to work with the domain experts in this area that are people who know a lot about fraudulent transactions or we would work with these people for our actual problem that we need to solve. These people, being experts, know that what data or data model that we get from the process is predictive. But since the data with which we start is raw and unstructured, it is never in the correct form as needed for actual processing. It could have duplicate data, or data that is missing, or else a lot of extra data that is not needed. The data could be formed from various sources which may also eventually end up being duplicate or redundant data.
In this case, there comes the requirement for pre-processing the data, so that the process could understand the data, and the good thing is that the machine learning products usually provide some data pre-processing modules to process the raw or unstructured data.
For instance, in capital markets there is always a need of price predictions for instruments or equities or assets and an algorithm is applied to the huge amount of unstructured data coming from various feed providers. In that case, multiple feed providers could provide the same data or some feed providers may provide the missing data and some the complete data. So, in order to apply the actual algorithm to the data, we need to have that complete unstructured data into a structured and shaped data for which a process of pre-massaging is required, through which the data is passed. Finally, we get a candidate copy of data which could be processes through the algorithm to get the actual golden copy.
After the data is pre-processed, we get some good structured data, and this data is now an input for machine learning. But is this a one-time job? Of course not, the process has to be iterative, and it has to be iterative until the data is available. In machine learning the major chunk of time is spent in this process. That is, working on the data to make it structured, clean, ready and available. Once the data is available, the algorithms could be applied to the data. Not only pre-processing tools, but the machine learning products also offer a large number of machine learning algorithms as well. The result of the algorithm applied data is a model, but now the question is whether this is the final model we needed.
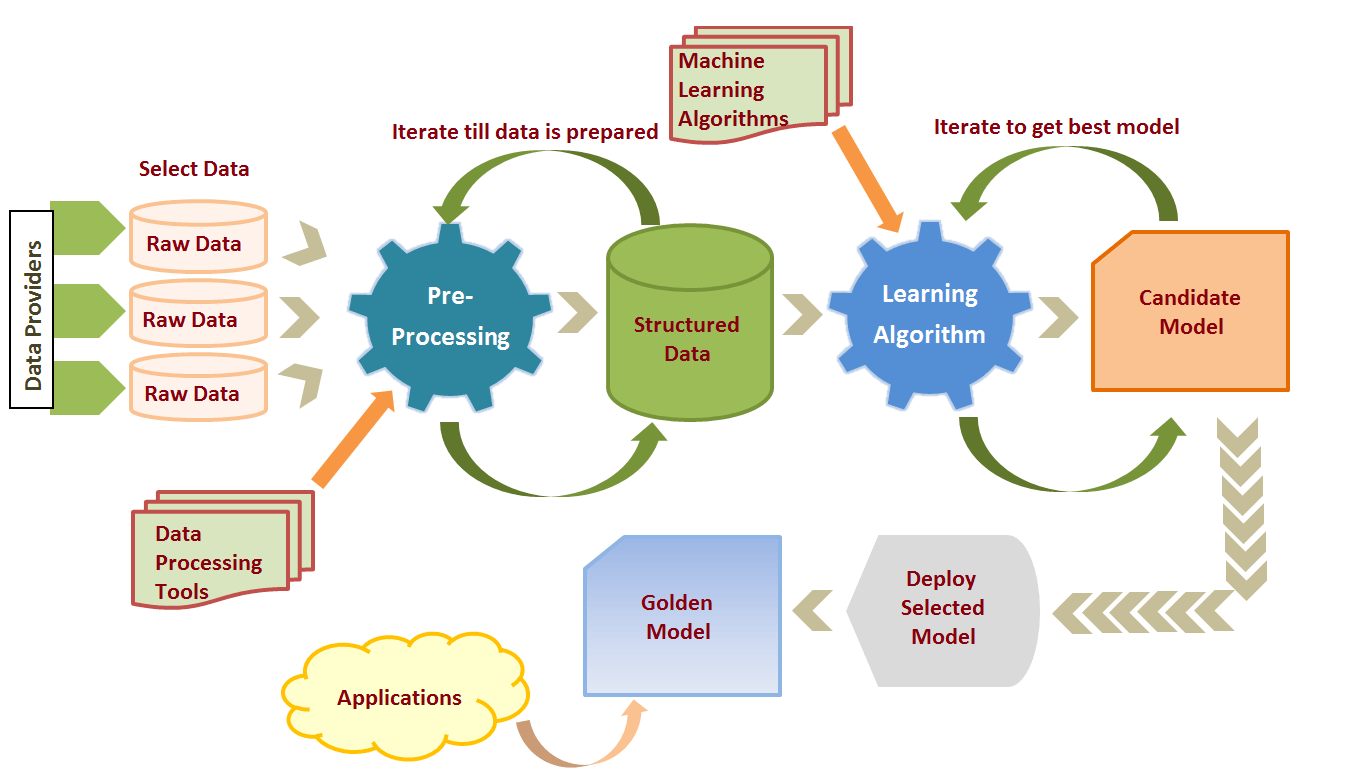
No, it is the candidate model that we got. Candidate model means the first most appropriate model that we get, but still it needs to be massaged. But do we get only one candidate model? Of course not, since this is an iterative process, we do not actually know what the best candidate model is, until we again and again produce several candidate models through the iterative process. We do it until we get the model that is good enough to be deployed. Once the model is deployed, applications start making use of it, so there is iteration at small levels and at the largest level as well.

We need to repeat the entire process again and again and re-create the model at regular intervals. The reason again for this process is very simple, it’s because the scenarios and factors change and we need to have our model up to date and real all the time. This could eventually also mean to process new data or applying new algorithms altogether.
Machine Learning: Scenarios
Let’s try to take a few scenarios showing how we can actually use machine learning.
Fraudulent Internet Banking Transaction
Let’s again take the example of fraudulent internet banking transaction. Let’s assume that we have certain number of bank customers using their internet banking facility to some third party payment application or gateway. In that case, there should be a point where the transaction should get rejected in case it is fraudulent. That’s the challenge: finding out the fraudulent transaction.

We could be in that scenario. First, we get all the historical transaction data and process through the machine learning process like we saw in earlier section, and eventually get a predictive model, that an application could later use to make decisions.
Predicting Customer
Let's see another such example, where the challenge is to find out how likely a customer is to switch. Let’s take an example of an internet data provider or a mobile company. In this space, customers usually call the call centers. For every customer, the call center employee needs to identify what are the chances of a customer to switch to a competitor.
Knowing that, a call center executive can, then, offer a better deal or offer some lucrative deal to prevent customer to switch and retain him. The challenge is how to identify those customers and the answer is again machine learning. The data provider or mobile companies usually have a lots of recorded calls data. The data may be vast and very detailed, so an application could be created around that data to consolidate it. This created application could use technologies like Spark or Hadoop or any other big data technology.

The company, then, may need to associate the consolidated data with more data, like data coming from the CRM’s to really create ample amount of right data that machine learning wants to use. This is not uncommon. Machine learning process can take data from multiple sources to process. As a result, there would be a predictive model that the application of call center could use to make decisions and predictions on customers likeliness to switch. It really adds value to the business and helps in overall growth altogether.
Conclusion
It’s all about asking the right question, and that acts as a beginning to machine learning process. After that, we need the right and structured data to answer the question, and this is the part which takes most of the time in a complete machine learning process. Then, the process with a number of iterations starts, until we get a desired predictive model. That model is updated from time to time, to adapt the changes that happen periodically, and finally the model is deployed. In the next article, we’ll focus on some terminologies and look at the machine learning process more closely.
Reference:









