



Data Literacy Starts With A Mindset
In the first part of this article, you faced a decision challenge: you were in charge of making a decision about which course to continue, and which one to discontinue, based on the following scenario:
You A/B tested two versions of the same course, Course A and Course B. In the busy workplace, you did your best to randomly select Cohort A members for Course A and Cohort B members for Course B. Both versions had identical pre- and post-assessments. Again, you did your best to control for any other differences between Course A and Course B except for the course design itself. The result of the A/B testing was the following:
-
- Cohort A (taking Course A) achieved a 25% average score gain comparing the pre- and post-assessment scores.
-
- Cohort B (taking Course B) achieved a 32% average score gain comparing the pre- and post-assessment scores.
Which cohort did better? And if you had to make a decision, which version of the course should be continued?
Which Course Performed Better?
Learning professionals sometimes don't have the luxury of participating in or influencing the full data lifecycle from the very beginning. This scenario throws you in at the end of a data project with limited information. While our initial reaction might be Course B is better because it has a larger learning gain, let's step back and start with the end: how do you define "better?"
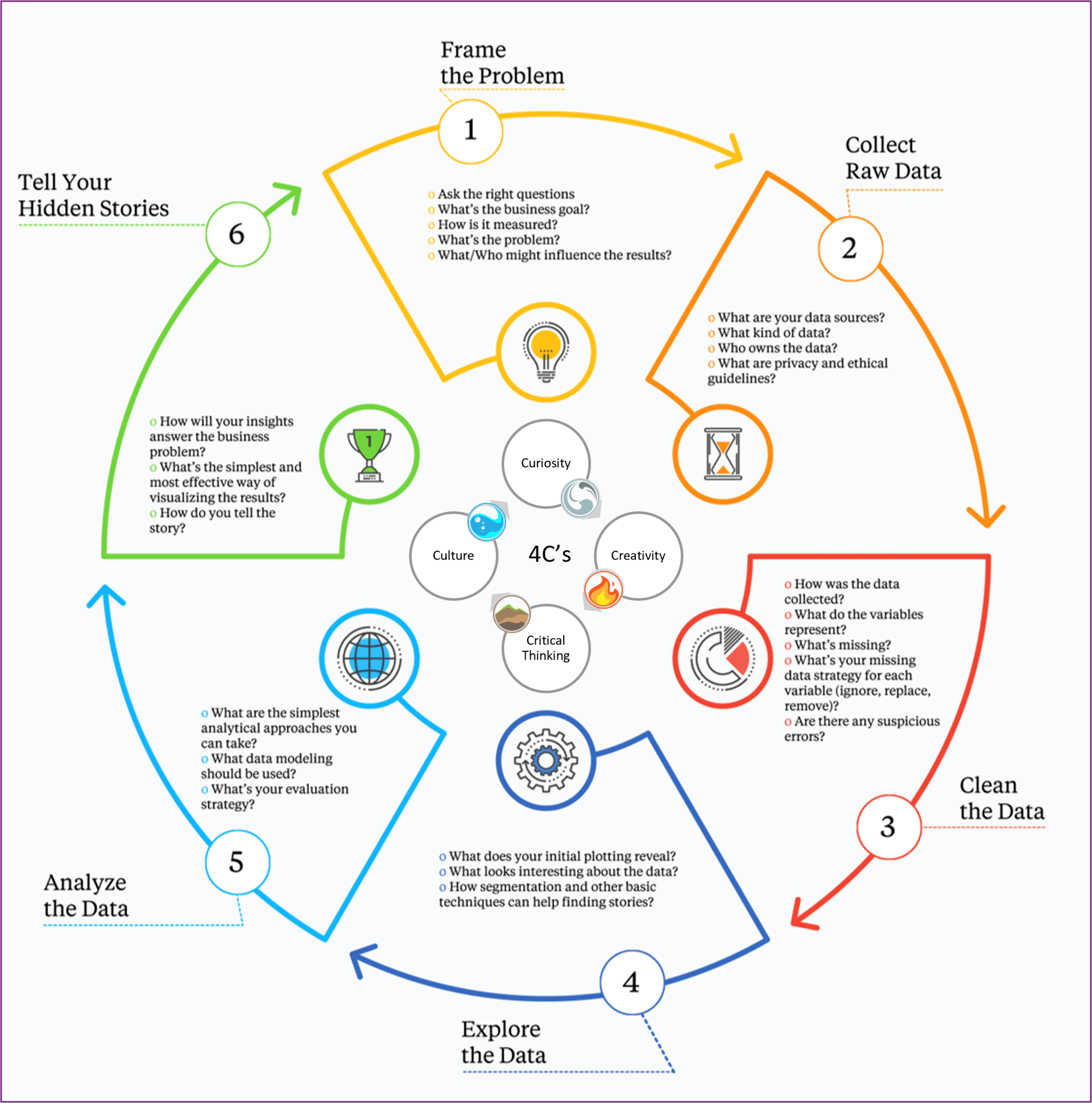
"Simplified" lifecycle of a data-driven project
Data literacy starts with a mindset, not with technology or statistics. Using the 4C's, we may need to ask a lot of questions before we can make a decision. For example, every single time someone says "better", you should ask this question: "how do you define 'better'?" Without defining what "better" means, you can't evaluate. At this point, the measurement is complete. The data is what it is, the process of collecting data is done. You can't change those! (Well, you could but you shouldn't.) Evaluation, however, requires an independent set of criteria (preferably agreed upon before measurement starts).
How Can You Evaluate Learning Outcomes?
Note: it's important to remember that just because you see change between the before and the after state of any learning program, it does not automatically mean that this change is significant (there's a statistical test for that), or that it is caused by the learning program itself. Ideally, collect data on different levels of participation: a) employees who did neither the assessments nor the learning activities; b) employees who did the pre-assessment and the post-assessment, but not the learning activities; c) employees who did the pre-assessment, but somewhere along the way dropped out from the learning activities; and d) employees who completed both the assessments and the learning activities.
Back to the Course A or Course B decision: in this scenario, you had two versions of the same course. Here are some of the different ways, generally, that you may use to evaluate the outcome:
- Raw score cohort average
The difference between pre-and post-assessments. - Individual raw score
The difference between pre-and post-assessments, followed by calculation of cohort average. - The number of employees reaching or exceeding the passing score
In the post-assessment (if there was any). - Normalized learning gain
Or normalized learning change. - Effect size
The list could continue. The first two evaluation criteria are the most common, probably because L&D has more control over the data needed for evaluation, and it is relatively simple to create an average for a cohort. The third one works if your focus is on whether learners meet or exceed the cut score (it's another story about how and why you set a cut score).
Since the scenario only provides us with average cohort raw scores, let's assume that in this case, we're looking at the average raw score difference between post- and pre-assessment. Whether it is the best way to measure effectiveness is another question. However, measuring and evaluating nothing is not a good alternative.
Now we have an agreement on how "better" is defined: the difference between pre- and post-assessment scores as cohort averages. One of the challenges we face now is that we only know the relative gain (raw average difference) for each cohort. There are two major pitfalls you should be aware of:
- While the average has its value, it can be misleading without knowing the number of participants and the distribution of the score. The fewer the participants, the higher the impact of an outlier (a data point that is far away from the mean).
- The raw average score difference can be largely influenced by the pre-assessment scores. The higher the pre-assessment score, the less "room" there is for improvement.
Can A 25% Be "Better" Than A 32% Gain?
Cohort A may have a 25% gain by moving from 65% to 90%. Cohort B may have a 32% gain by moving from 52% to 84%. As a result, Cohort A ends up with a 90% post-assessment average; meanwhile, Cohort B ends up with an 84%. Which one is better? If we define better as the relative gain, Cohort B wins with a final outcome of 84%, even if Cohort A's actual post-assessment average is higher at 90%.
Lesson learned
If any time someone reports the raw score average difference, you should approach the findings with an open mind, but not with an empty head. You should ask for more details.
Another problem with raw averages is the challenge of comparing different course performances. Let's say two courses achieved the same gain: 37%. Is it fair to say they were equally effective, even if one moved from a 40% to a 77%, and the other from a 62% to a 99%, average? The first course had a 100 - 40 = 60% gap to close, while the second one had only a 100 - 62 = 38% gap to close.
How Do You Mitigate The Pre-Assessment Influence?
Out of scope for this article, but I suggest learning about normalization and effect size, the methods for options 4 and 5 mentioned above in the evaluation list. This article does a good job of comparing some of the most common measurement and evaluation methods.
So, the short answer to the challenge is that we don't have enough data in the scenario to make a decision. Was the exercise useless, then? No. It was data literacy in action: asking the right questions is the first step, before any analysis, dashboard, and decision-making.
What Should A Data Literacy Program Include For Learning?
If you're looking for a data literacy program for yourself, or you're planning to build one for your learning team, I suggest the following guidelines:
- Data literacy is not the goal of a data literacy program.
It is the starting point. Therefore, you need a vision first: the "why" behind starting out on this adventure. For my team, it was the first step before implementing a learning and evaluation framework (LTEM). - You'll need a data literacy framework.
This is needed to guide you through the components. There's no need to reinvent the wheel. The two books I recommend with practical frameworks inside are Data Literacy in Practice by Angelika Klidas and Kevin Hanegan, and Be Data Literate by Jordan Morrow. - You'll need meaningful, authentic activities to practice fundamental data classification, measurement, and basic statistical methodologies.
For our team, I created a fake pilot program with fake data, a fake dashboard, and a fake narrative. At the core, as an entry point for the adventure, was a dashboard. Just like in the challenge above about the cohorts, the best way to involve non-math/non-stats/non-analytical learning professionals is through authentic challenges, like a dashboard they see often. You don't need to teach everything about data literacy in a data literacy program before they can apply the principles. - Once the whole team speaks the same data language you can build on the foundations.
Do so by working through a case study that involves creating a data strategy, acquiring data, cleaning and validating the data, exploring the data, analyzing it, and turning it into insights. This is where learning analytics happen. - Finally, you'll need the team to tell a compelling story.
Use those insights to influence a decision. This is where data storytelling is important. - As a follow-up, you can close the project with an evaluation.
Were the insights correct? What was the outcome? What was missed? What would you do differently next time?
Again, I strongly suggest learning data literacy through hands-on applications rather than taking courses about data literacy.
"What if I use data and make mistakes?" is a common question. First of all, not evaluating any data and just using gut-research to make decisions is already a mistake. Second, start with lower stake programs with lower risk and "two-way door" consequences. I also suggest finding some experts who are willing to guide you.
For sections 4–6 above, learning professionals now have a book written by Megan Torrance about data analytics [1]. The reason I like Megan's book is because it is written by a practitioner and it is written specifically for Instructional Designers and not general data people. It is filled with examples and practical tips on how to start your data analytics journey. Finally, if you want to test out an existing data literacy program that includes hands-on activities, you may want to try DataCamp's data literacy program.
Should You Use A Real Project Or A Fake One For A Data Literacy Program Case Study?
When it comes to a worked example you want your team to experience, you'll need to consider whether to use a real project or come up with a fake (fictitious) one. A real project brings authenticity for sure. However, it often has unintended consequences. First, a single project may not have all the teaching points or hidden stories you want your team to experience. Second, because it is real, it may pose some ethical issues related to data privacy and other factors. You may also run into defensive mindsets about how and why certain learning solutions didn't work.
A fake project, on the other hand, requires a lot of extra work, because you have to generate data that acts real. If the fake project is not authentic enough, you may run into the "this is not how it works here" defensive attitude. If you make the fake project too abstract, your audience may not care about the outcome in the first place. In my design, I chose to do a narrative-driven, spaced learning journey approach. The fictitious, narrative-driven framework had a choose-your-adventure vibe, which can lower the self-defense shield of "this is not how it works here" or "we've always done X this way here."
Adaptive, Combined Learning And Application
The design was a spaced journey over time, because the point was not to take another course to pass a test. The point was to learn and apply over time, iteratively. The adventure engine made the journey adaptive. Based on previous experience, current role, and current skill levels, individuals had a different route from the beginning. Ultimately, in the end, they had to decide whether the pilot was effective, or not to be implemented.
Another important element worth mentioning is the social component. Asynchronous learning enabled individuals to proceed at their own pace but also to learn from each other, discuss, reflect, and share in Slack. In fact, in one of the activities, each individual was allowed to interview stakeholders by selecting a maximum of four questions to find out more about the context and goals. However, nobody stopped the participants from getting out of the silos and sharing their individual responses in Slack.
The Data Hurdle
Since the core of the adventure relied on the pilot data, I needed a tool that was capable of creating specific data patterns for the story. A year ago, we didn't have ChatGPT yet, so I went with an app called Mockaroo [2]. If you ever need a fake dataset for anything, this app is worth a try. You create your empty sheet with the columns you need and tell the app to fill it with X number of rows. You can set the mean of the dataset you want, the standard deviation, and even the percentage of blank for each field, and the app will make sure the data fits the requirements. I used that, for example, to get "feedback" from 30% of participants.
Once you're satisfied with the data, the next step is visualization. I'm working with ChatGPT now to replicate the data I need, but I still think with all the specifics, it was easier to do it with Mockaroo. At Amazon, we use QuickSight, but any business intelligence tool can work. You upload the data and create a typical dashboard. Intentionally, I made the dashboard an average visualization and data storytelling resource. Something that hints at the real story but hides the obvious evidence.
For an in-person version of this adventure, I also created a gameboard (basically, a dashboard in real life) with data cards. In my sessions at the ATD TechKnowledge and International Conference and Expo, teams sitting around a table were using these data cards to decide if they were true or not based on the data on the dashboard. They reflected, interpreted, analyzed, and argued using the data while trying to influence each other to reach a unanimous decision. And that is what data literacy is about: using data along with storytelling to make a difference.
References:
[1] Megan Torrance. 2023. Data Analytics for Instructional Designers. Association for Talent Development.
[2] Mockaroo
Image Credits:
- The image within the body of the article was created and supplied by the author.
Editor's Note: The apostrophe with single capital letters to indicate the plural is a deliberate departure from our house style, at the author's request.







