


Transforming Learning: 3 Cognitive Learning Theories
In cognitive learning theories, learning is described in terms of information processing. In a nutshell, when we receive external data, our minds process it, discard it, or store it. Information is processed initially in working memory (WM). Information that is to be retained is then passed on to long-term memory (LTM).

Transforming Learning: Video For Cognitive, Emotional, And Social Engagement
WM has a relatively small storage capacity (roughly five to ten pieces of information) and a brief retention period (Driscoll, 2005; Ibrahim, 2012; Sweller, 2010). We use two strategies to make WM more effective: rehearsal and chunking (Driscoll, 2005). Rehearsal is simply mental repetition of information in order to remember it. Chunking involves breaking large pieces of information into smaller pieces.
A common example of chunking is telephone numbers. Trying to memorize a group of ten numbers (say, 5854140651) can be difficult. The task becomes easier when the numbers are put into smaller groups: 585-414-0651. When moved to LTM, information must be encoded or stored in memory, in some way. The model most commonly used in discussions of cognitive learning theory is schema theory. In this model, information is grouped into meaningful categories, or schemas (Kalyuga, 2010). As shown in Figure 1, new information is either added to an existing schema, or perhaps a new one is created.
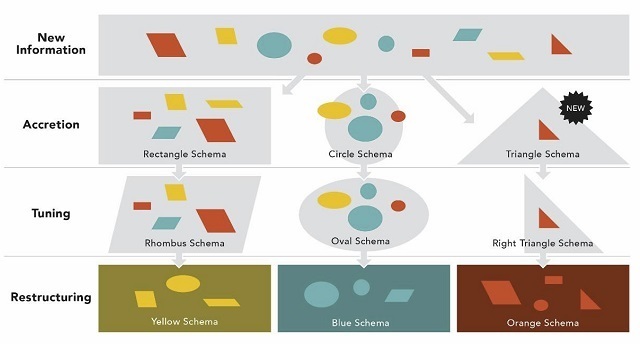
Figure 1. Schema theory / Credit: Obsidian Learning
Learning, then, can occur in one or more of three processes: accretion (adding a new fact to an existing schema), tuning (changing the existing schema so that it becomes more consistent with experience), and restructuring (creating entirely new schemata that replace or incorporate old ones) (Driscoll, 2005).
Limitations Of Cognitive Processing
Because WM is limited, learners use various strategies to select and store relevant data. The Instructional Designer can use a number of techniques to enhance learning by simplifying the learner’s assimilation of information into their schemas.
These strategies include concept mapping (graphically displaying the relationships between the elements of a system) (West, Farmer, & Wolf, 1991), advance organizers (introductory material that bridges the gap between what the learner already knows and is about to learn) (Driscoll, 2005), metaphor and analogy comparing new information to information already learned, chunking, rehearsal, imagery (providing opportunities to mentally visualize material or concepts), and mnemonic devices. Drawing from several theoretical approaches, researchers have grappled with ways to enhance learning given our innate cognitive limitations.
In this article, we will look at a few of these theories:
- Dual coding theory
- Cognitive load theory
- Cognitive theory of multimedia learning
1. Dual Coding Theory
The seminal research of Allan Paivio on “dual coding” beginning in the late 1960s has had a profound impact on theories about how multimedia contributes to learning. The large body of research conducted by Paivio and his colleagues over the years has been brought together in Mind and its evolution: A dual coding theoretical approach (Paivio, 2007), which informs the following discussion. As illustrated in Figure 2, dual coding theory suggests that we learn through two cognitive systems: verbal and nonverbal.
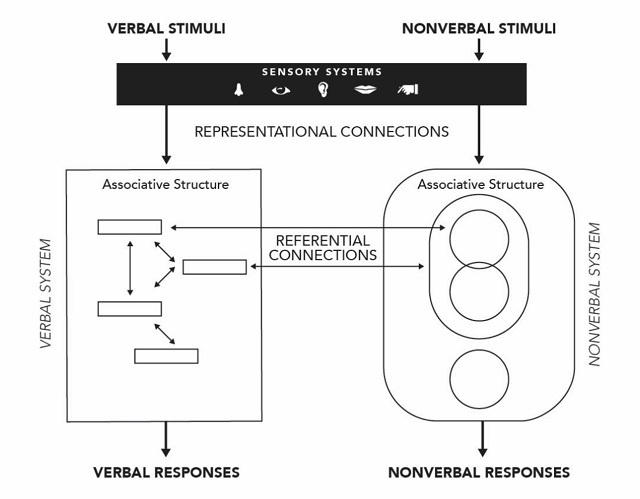
Figure 2. Structural model of dual coding theory. Adapted from Paivio (2007). / Credit: Obsidian Learning
We receive verbal and nonverbal stimuli through several sensorimotor systems – visual, auditory, haptic (the feel of objects), gustation (taste), olfaction (smell), and emotion – and we make representational associations of these stimuli with cognitive structures in our minds. The representational associations of verbal stimuli take the form of words, facts, concepts, ideas, and the like, while the representational associations of nonverbal stimuli are such things as visual and auditory images, emotional sensations, and the “feeling” of touching objects.
Representational associations are dormant until they are activated, or consciously associated with something external. Activation occurs both “vertically” from a system to external stimulus – for example, associating an internal image of a cup with an actual cup – and “horizontally” between systems, as in associating the image of the cup with (for English speakers) the word “cup.” A variety of associations usually occurs: seeing the word “cup” can recall the sound of the word when spoken. Likewise, hearing the word can recall an image of a cup. Further, there could be sensory or emotional associations with the word and the image: slaking thirst, warmth, coldness, comfort, and so forth.
These cross-system activations reinforce and strengthen the learning of facts, words, procedures, etc. – and the more activations the merrier as far as learning is concerned.
As an example, consider an infant gathering verbal and nonverbal stimuli. The infant looks repeatedly at an object – in our scenario, a cup – until he or she recognizes it as something distinct from other objects, like plates, tables, cats, etc. In time, the infant learns the object is typically used to hold liquids and is called a “cup.” The infant hears the sound of the word and learns to say it. When the child learns to read and write, he or she gains additional visual and nonverbal associations. The three phonemes that make up the word (we might represent them as “k” and “uh” and “p”) are visually represented in writing as “cup.” Seeing a cup can trigger internal “hearing” of the word or “seeing” it in written form. Learning to write the word adds further psychomotor associations to the verbal and nonverbal ones.
Principles of DCT have been applied to instruction, and particularly to using multimedia for learning. While we remember pictures better than concrete words by as much as a 2-to-1 ratio (Paivio, 2007), it is by engaging both audio and visual channels (as video does) that learning is most effective.
2. Cognitive Load Theory
As noted above, our WM capacity is limited. The first attempt to measure just how limited it is appears as Miller’s (1956) classic “magical number” of seven plus or minus two items that can be juggled in WM at one time. Over time, conceptions of WM limitation have changed – for example, Paas and Ayres (2014) state that four plus or minus one items can be processed at the same time for about 30 seconds. Regardless of the precise “magical number,” we know both from research and personal experience that we cannot simultaneously process more than a few elements. Research on cognitive load theory (CLT) has suggested ways in which instruction can be designed to maximize the productivity of WM by minimizing extraneous or distracting information. Learners are thus enabled to process and store relevant knowledge in LTM. There are 3 types of cognitive load (Moreno & Park, 2010; Paas & Ayres, 2014):
- Intrinsic load is difficulty that is inherent in the content itself.
- Extraneous load is information or activity that is not needed for learning.
- Germane load is cognitive processing that assists in the formation of learner schemas.
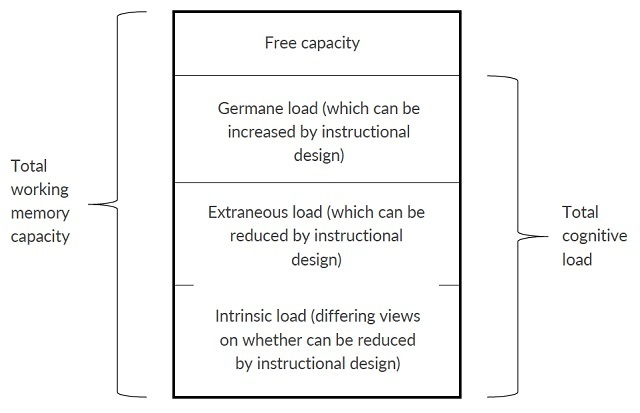
Figure 3. Cognitive load theory model. Adapted from Moreno & Park, 2010. / Credit: Obsidian Learning
3. Cognitive Theory of Multimedia Learning
Drawing on CLT, dual coding, and other cognitive theories of learning, the experimental research of Richard Mayer (2009) has led to his cognitive theory of multimedia learning (CTML). The overarching principle of multimedia learning is that we learn more effectively from words and pictures than from words alone. Mayer refers to essentially the same types of cognitive load as those of CLT, though he uses slightly different terminology:
- Extraneous processing (equivalent to extraneous load of CLT)
- Essential processing (equivalent to intrinsic load of CLT)
- Generative processing (equivalent to germane load of CLT)
As shown in the following tables, Mayer has developed twelve principles of multimedia learning to facilitate these three types of processing.
| Principle | Description |
| Coherence | Learning is improved when extraneous material is removed. Extraneous material includes interesting but irrelevant words, symbols, pictures, sounds, and music. |
| Signaling | We learn better when visual or textual cues that highlight content organization are included. These cues assist the learner in schema development. |
| Redundancy | We learn better from graphics and narration than from graphics, narration, and printed text. The visual channel can be overloaded when the learner must process both text and graphics. |
| Spatial contiguity | We learn better when related words and pictures appear near each other because the learner does not have to use cognitive resources to put related elements together. |
| Temporal contiguity | We learn better when related words and pictures are presented simultaneously rather than successively. Presenting related items simultaneously allows the learner to hold mental representations of both in WM together. |
Table 1. Principles for managing extraneous processing (Mayer, 2009)
| Principle | Description |
| Segmenting | We learn better when content is presented in user-paced segments rather than as a continuous unit. Segmenting allows learners to see the causal relationship between one step and the next. |
| Pre-training | We learn more deeply when we know the names and characteristics of the main concepts. Introduce the structure and define key terms before presenting concepts. |
| Modality | We learn more deeply from pictures and spoken words than from pictures and printed words. With pictures and spoken words, information is processed through two channels, allowing more efficient processing. With pictures and printed words, information is processed only through the visual channel. |
Table 2. Principles for managing essential processing (Mayer, 2009)
| Principle | Description |
| Multimedia | We learn better from words and pictures than from words alone. Words and pictures allow us to create both verbal and visual mental models and to build connections between them. |
| Personalization | We learn better from multimedia when words are in conversational rather than formal style. When we feel the narrator is speaking “to us” we see the narrator as a conversational partner and make a stronger effort to understand. |
| Voice | We learn better when narration is spoken with a friendly human voice than with a machine voice. |
| Image | We do not necessarily learn better when the speaker’s image is on the screen. Doing so can split the learner’s attention between the speaker and relevant, content-related images. |
Table 3. Principles for managing generative processing (Mayer, 2009)
CTML And Video Design
Ibrahim (2012) has applied CTML principles specifically to the design of instructional video and has isolated 3 key principles in what he calls the SSW model of design:
- Segmentation.
Divide instructional material into smaller, more understandable pieces. We sometimes refer to this as “chunking” of information. - Signaling.
Visual and verbal cues on the structure of the content (also called “advance organizers” as noted above) focus the learner’s attention on relevant content. - Weeding.
Related to the CTML coherence principle, weeding involves the removal of extraneous information in order to focus the learner on relevant content.
If you want to learn more learning solutions that can be used in blended learning environments, download the eBook Transforming Learning: Using Video For Cognitive, Emotional, And Social Engagement.
Related articles:
1. Transforming Learning: Applications Of Instructional Videos
2. 5 Stages Of Instructional Video Development Process – Feat. A Case Study
3. Software Tools For Instructional Video Design And Development
4. eBook – Transforming Learning: Using Video For Cognitive, Emotional, And Social Engagement









