



Turning Faster Content Into Real Behavior Change
Readiness debt is the gap between what training is meant to change and what actually changes in behavior or performance. It is training without transfer, and it is easy to miss. Employees need new skills to stay competitive (49% of L&D leaders say executives are concerned employees don't have the right skills to execute business strategy [1]), but L&D struggles to quickly and consistently prove whether training is building those capabilities in the workflow.
Measuring impact has always been hard. Completions get counted. Sentiment gets collected. But whether the work changed as a result of the learning experience? That's harder to see. When proof of knowledge transfer is mostly self-reported, the data is biased and inconsistent. [2] That makes it hard to build a reliable view of what's working, and that's where readiness debt starts.
AI content tools compound this debt, widening the gap between shipping learning and proving knowledge transfer. In Synthesia's survey of 400+ L&D practitioners, 88% of respondents said AI is already delivering value through time saved creating content. At the same time, 63% of respondents said they need support measuring impact.
That's the shift we're not talking about enough: what happens after launch. When content is easier to produce at scale, readiness depends on a repeatable way to learn from what happens next and update the intervention while it still matters.
The Hidden Cost Of Faster Content
AI has made the early stages of ADDIE (Analyze, Design, Develop, Implement, Evaluate) feel lighter. Drafting scripts, shaping objectives, and turning SME input into a usable first version now moves faster, especially text-to-video tools. Localization can happen earlier, rather than as a last-mile scramble. For many teams, that creates real capacity, even when headcount remains unchanged.
The hidden cost is losing a clean before-and-after. When content changes quickly without clear guardrails, measurement stops being comparable, and it gets harder to tell what is working. So reporting defaults to visible metrics like what shipped and how learners rated it. Leaders ask for those numbers because they're under pressure from executives to prove business impact, even when those metrics don't show transfer.
That pulls attention toward visible delivery and away from follow-through. The result is predictable: teams keep producing new learning, while evaluation and iteration lag behind.
Synthesia's research shows the tension clearly: teams can create faster than they can evaluate what's working in the workflow. In 2024, practitioners spent less than 10% of their time on evaluation. In 2025, GenAI has changed what's possible in design and development, but that shift hasn't carried through to evaluation. Only 19% of practitioners report using AI tools in evaluation.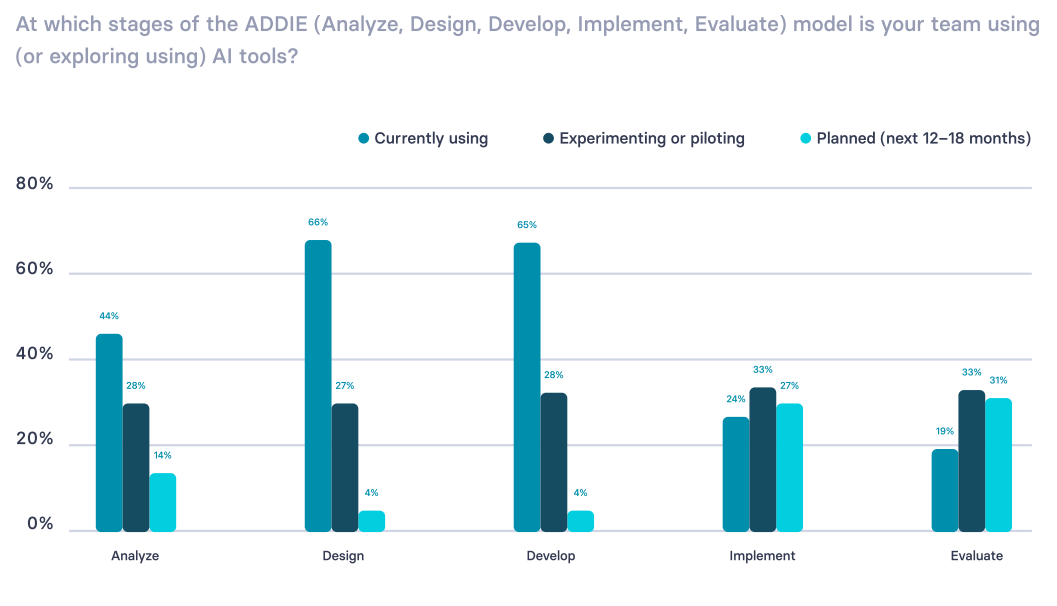
Source: From Experimentation to Everyday: How AI Is Transforming L&D, AI in Learning & Development Report (2026)
AI has expanded capacity in the parts of the work that are easiest to accelerate, while proving transfer and improving the intervention still moves slowly.
One way to close that gap is to treat measurement as part of the learning design. If evaluation stays delayed, the capacity AI creates gets absorbed by more production.
Here's how we think about it at Synthesia. We've built a tool that speeds up training production, with analytics built in. That's a starting point, not the strategy. L&D still has to map learning to the capabilities the organization needs and define what "good enough" evidence looks like in the workflow. From there, analytics like drop-off points and replays can guide what to change next.
Measurement Starts In Design
Measurement only becomes useful when it is designed into the work. Otherwise, you end up reporting what is easy to capture, instead of what helps you make decisions. The goal is to raise the quality of evidence without over-engineering it. Here are a few ways to do that.
1. Define What Should Change
A common source of readiness debt is management capability. We rely on managers to coach performance, reinforce priorities, and carry change into day-to-day work. "Being a good manager" is a set of behaviors that shows up in small moments, which is why it can be hard to measure even in engagement surveys or performance reviews.
So break the outcome down into a behavior you can observe and revisit, using this template:
When [role] is [in situation], they can [do X] so [Y outcome] happens.
Examples
- Coaching and feedback: When a manager spots a miss, they give specific guidance within 24 hours so the employee can correct it on the next attempt.
- Psychological safety: When someone raises a concern, the manager responds without blame so risks get surfaced early instead of hidden.
- Goal and expectation setting: When priorities shift, the manager restates what "good" looks like for the week so decisions stay aligned.
- Enablement and barrier removal: When work is blocked, the manager removes the constraint or routes it to the right owner so progress resumes quickly.
- Recognition and reinforcement: When someone applies the new standard, the manager names what was done well so the behavior repeats.
2. Decide What "Good Enough" Looks Like
"Good enough" evidence is something you can collect consistently enough to make a decision. If you don't define it up front, measurement defaults to what's easiest to report later. Start with two inputs you can revisit: one from the workflow and one from the learning experience.
Example (Coaching And Feedback)
- One signal from the workflow: Track whether coaching is happening when it should. Measure the share of performance issues that receive documented, specific feedback within 24 hours—and the repeat rate of the same issue on the next attempt.
- One signal from the learning experience: Look for where managers struggled with the skill itself. Review where they drop off in the module, which practice scenarios they replay, and which checks they miss on "specific vs. vague feedback."
Then write the decision rule in plain language:
If we see [pattern] for [time period], we will [revise/reinforce/retire] the intervention.
This turns measurement into follow-through. It also sets you up to use AI tools to support this work by spotting patterns and turning them into evidence for decisions.
3. Use Version Control
Defining "good enough" evidence only helps if you can trust what you're comparing. That's where version control comes in. When content changes without clear version labels, outcomes stop being comparable. In global organizations, that risk increases as content gets adapted across regions and languages. Translation tools make those updates faster, which makes versioning even more important.
Keep it lightweight:
- Assign an owner for the asset.
- Define what counts as a new version (for example, changes to steps, examples, or expectations).
- Add a one-line change note: what changed and why.
- Make sure there is sufficient time to assess the intervention.
Example (Coaching And Feedback)
A new version of the coaching and feedback module might add a short "what to say" model for performance conversations, because HR business partners are hearing the same pattern: managers are addressing poor performance with language that is too vague to act on. Label the new version clearly (Manager Coaching v1.2), with a one-line note: "Added performance-conversation model language to reduce vague feedback."
4. Schedule Follow-Through
Readiness debt shrinks when iteration is planned:
- Set the first review date before launch. Put it on the calendar before you publish.
- Name a decision owner. One person owns whether the asset gets reinforced, revised, or retired.
- Agree on triggers for change. Use the "good enough" rule from Step 2 so updates aren't ad hoc.
- Plan a second touch. Reinforcement should be built into the intervention, not bolted on afterward.
5. Use AI To Shorten The Feedback Loop
With ownership and a review cadence in place, AI can speed up follow-through. Here are ways to use it after launch:
- Summarize what changed in the work. Feed in anonymized themes from HR business partner notes, manager questions, support tickets, or QA comments. Ask for the top repeat issues, the language people use, and what looks like a skill gap vs. a will gap.
- Turn patterns into hypotheses. Ask AI to propose the most likely reason the behavior is not shifting, then list what evidence would support or reject this hypothesis.
- Draft targeted revisions. Use AI tools to rewrite the section that is failing, generate sharper examples, and produce a short reinforcement follow-up. Keep the change tied to a specific pattern you observed.
- Create role-specific prompts. Generate coaching prompts, checklists, and "what to say" models that match the scenarios employees are facing.
- Produce a decision brief. Have AI generate a one-page summary: what you saw, what you changed, what you expect to happen next, and what you will check in the next review.
Example (Coaching And Feedback)
HR business partners report managers are still using vague language in performance conversations. You use AI to synthesize the recurring phrasing, draft a stronger "what to say" model, and produce two short practice scenarios. You publish as Manager Coaching v1.2, then compare drop-off and check results against v1.1 to see whether the same HRBP pattern shows up less often.
Closing The Gap
That's how you reduce readiness debt. None of this requires a new platform or a bigger team. Align measurement with design so learning has a baseline and a path to improvement. Over time, that becomes a sustainable learning ecosystem that builds capability and makes change stick.
AI can support that cycle. Use it for the work humans shouldn't spend hours on: synthesizing feedback, spotting recurring patterns, summarizing what changed between versions, and drafting targeted updates for review. Your team still sets the standard for what counts as evidence in your workflow.
Key Takeaways
- Readiness debt comes from a mismatch between training activity and what changes in the workflow.
- Measurement becomes useful when it is planned up front, tied to a baseline, and revisited after launch.
- Version control keeps evidence comparable and updates interpretable.
- AI is most valuable when it reduces the friction of iteration and helps teams act on what they learn.
If you're feeling overwhelmed, start this week with one program. Define the change you want to see in the workflow, then decide what evidence of that change looks like. Set a realistic cadence for revisions and re-publishing based on what you learn.
References:
[1] Workplace Learning Report 2025
[2] Transfer of workplace e-learning: A systematic literature review









